Gasper Part 1
This blog is a cross post from the SDSLabs blog post and is Part 1 of a series. It gives an idea of Gasper’s architecture, technical stack, and capabilities. The subsequent parts cover the detailed discussion of its various components.*
Introduction#
Providing simplicity without letting go of the necessities in deployments has always been a bottleneck for PaaS providers. Imagine you have a couple of Bare-Metal servers or Virtual Machines at your disposal (collectively called here as nodes) and you wanted to setup an application hosting service, such that the load is evenly distributed among all nodes.
Let’s face it; we have essentially two choices.
Manually Setup Everything:
Manually decide which application goes to which node, then use ssh/telnet to manually setup all of your applications one by one.
Kubernetes at the rescue:
Kubernetes takes away the load distribution problem with its intelligent clustering. But then again, it requires a lot (and yes a lot!) of configurations for each application. Besides, the pipeline for setting up the app still needs to be implemented.
Gasper - A New Hope
Gasper addresses all of the above problems and makes deploying applications just a breeze. The platform is modeled as a REST API, where the user just needs to provide the Github repository’s URL, build commands and some optional configurations, click the Create button and voila, your application is deployed!
Sounds cool? Let’s look at the amazing tale under the hood#
Overview of the Architecture
Gasper is written entirely in Go - the language of the Cloud. It essentially has a microservices-based architecture. If you don’t know already, we have multiple software design paradigms. One is the monolithic architecture, the whole application as a single unit with multiple modules. These applications lose flexibility easily and are difficult to scale. Next, we have the microservices architecture. Each module is a separate unit and interacts only with APIs. Technically, we say that we have decoupled the modules. This can be scaled easily, and each module can be designed separately.
This choice of architecture was made right during the initial phase due to multiple factors. One of them being: this makes adding more modules dead simple. Suppose we need a service for internal DNS resolution. We create a separate module for that and just plug it in! Apart from this, as it scales and spans multiple servers, the services automatically handle the load distribution making everything a walk in the park.
The microservices in action
The journey from downloading the source code to its final deployment in Gasper involves the following microservices:
- Kaze 🌪 (the master service responsible for managing all other services)
- Mizu 💧(the worker service for creating/managing apps)
- Kaen 🔥(the worker service for creating/managing databases)
- Enrai ⚡️(the reverse proxy server)
- Hikari 💡(the service for internal DNS resolution)
- Iwa 🗿(the service that handles ssh into the containers)
Now that we are done with the architecture, let’s start from the very core itself: How to package? Multiple apps in a single node or one app per node. The former just sends security on a walk, and the latter one brings about a lot of hardware overheads.
H’re cometh Docker…
Docker is a service that deploys containers. Containers are a sort of OS-level virtualization. Docker comes with a plethora of configuration options, from limiting the allocation of CPU and Memory resources to managing security levels, and much, much more. It was a perfect solution to our problem; containers have a low resource overhead and implement isolation for configuration files and dependencies.

With docker containerization at its core, apps now can be packaged and built.
Alright let’s deploy, shall we?#
The generic pipeline that Gasper follows for app deployment is as follows:
- Download the application source code
- Mount this source code as a volume for the container
- Bind the ports of the host and the container
- Start the docker container with this configuration
- Install the dependencies
- Fire up the application
And hola, your application is live!
Generally these build instructions are mentioned in a Dockerfile, which is quite robust per se. But we wanted to get rid of that nasty Dockerfile and the docker-compose heavy lifting, right? Let’s automate this pipeline.
Golang’s Docker Engine library was enough to handle steps 2 through 6. Gasper has two separate microservices, Mizu and Kaen, to manage the stepwise deployment of apps and databases respectively using these library functions. More details on them are in the next blog.
However, the whole process initially took a whopping 15s, even for simple boilerplate apps. We needed to optimize that.
Go, go, go… making thy w’rk easy
Go, besides the fact that it came from Google, is famous for its efficient realization of concurrency using Goroutines. And there it was, we took the two slowest processes, steps 1 and 4, and put them in goroutines. The deployment times came down from ~15s to ~5.5s. Further optimizations pulled it down to 1.5s. Phew! That was fast.
The final take:#
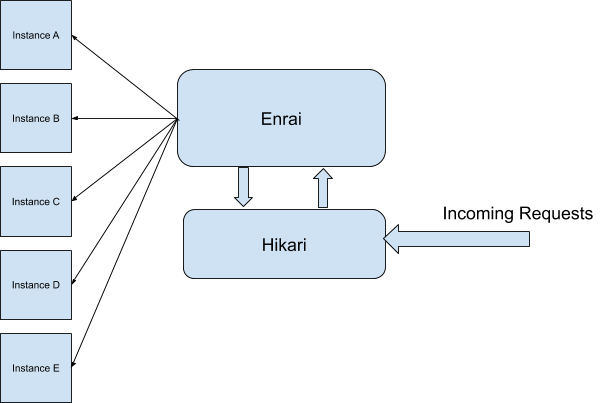
The next we have Enrai, the reverse proxy server. Among all the services, only Enrai is given a public IP and the rest of the apps are proxied through it. Laying it down simply, it is a server that receives requests from clients and forwards them to the respective instances (containers in our case).
Gasper boasts an internal DNS resolution service, too, Hikari. It allots domain names to the apps and databases and maintains the DNS records, ensuring an even distribution.\
A lot things coming up altogether? This diagram might ease out things:
For those who prefer a hands-on deployment experience, Gasper provides SSH into the containers along with a virtual terminal for ease. Iwa plays its role here.
This marks the end of the deployment journey. The user is always able to restart/rebuild the app in case of failure, and there’s always SSH if they want to get their hands dirty 💪.

Part 2 of the series deals with the internal working of the services. In Part 3, we will discuss how we acquired logs and metrics, and how it actually builds your cloud with intelligent load distribution.
You can find the project here: github.com/sdslabs/gasper. If you happen to like it, a star on the repository is always welcome 😛.